2月5日,可灵AI上线3.0系列模型。据了解,此次发布的可灵视频3.0、可灵视频3.0 Omni及可灵图片3.0、可灵图片3.0 Omni模型,覆盖图片生成、视频生成、编辑及后期等影视级全流程链路,标志着AI正式进入影视与创意内容的核心生产环节。
据了解,可灵3.0系列模型作为多模态输入与输出高度统一的一体化视频模型体系,并非将功能简单叠加,而是通过统一架构,将影像创作中的理解、生成与编辑整合为一个连续流程,可使用户在单一模型内完成创作。
这也意味着,创作者可以同时使用文字、图片、声音与视频作为输入内容,并直接获得可用的专业影像级输出结果,创作过程不再被拆分为多个工具与步骤。
一直以来,使用AI模型进行视频或图片创作的用户,最关心的就是模型的稳定性与表达力。此次,可灵3.0系列模型的上线增强了视频内容的一致性,通过整合视频主体、音色绑定及“图生视频+主体参考”等一系列技术能力,使得人物形象、动作与声音在复杂镜头切换中保持稳定,文字清晰、品牌标识可识别,即便在多语言场景下,视觉风格与角色特征也能高度统一。
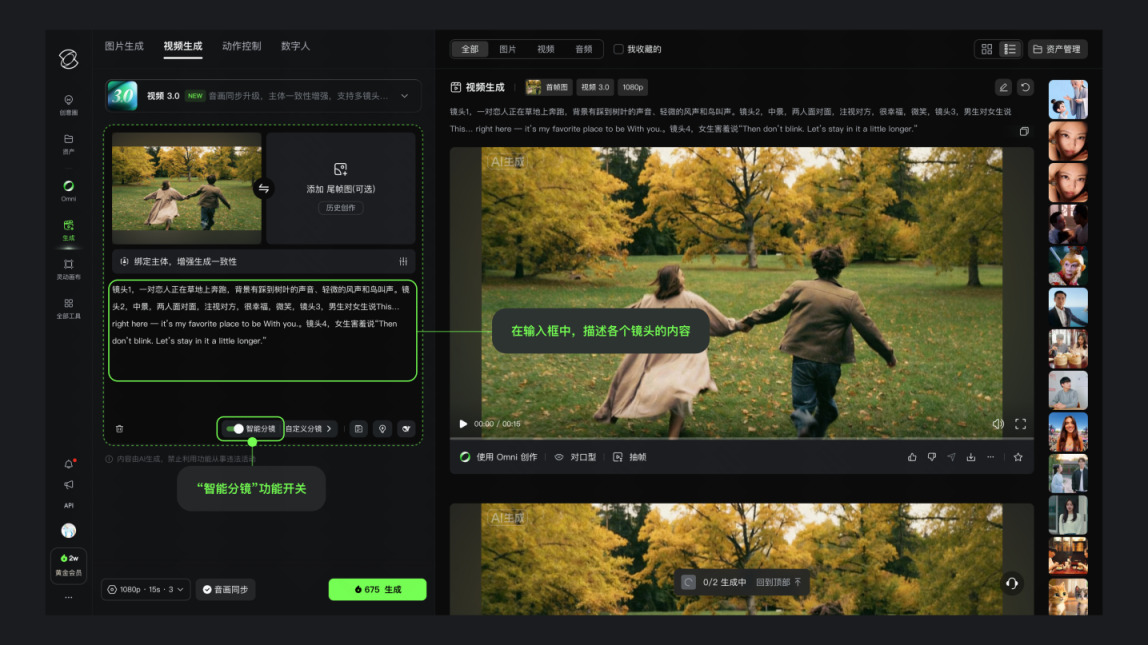
此外,该模型支持最长15秒视频的连续生成,并引入智能分镜与自定义镜头控制,让创作者能够直接组织镜头节奏与叙事结构,不再依赖碎片化拼接,从而让镜头具备情绪递进与画面张力。
2月5日,可灵AI上线3.0系列模型。据了解,此次发布的可灵视频3.0、可灵视频3.0 Omni及可灵图片3.0、可灵图片3.0 Omni模型,覆盖图片生成、视频生成、编辑及后期等影视级全流程链路,标志着AI正式进入影视与创意内容的核心生产环节。
据了解,可灵3.0系列模型作为多模态输入与输出高度统一的一体化视频模型体系,并非将功能简单叠加,而是通过统一架构,将影像创作中的理解、生成与编辑整合为一个连续流程,可使用户在单一模型内完成创作。
这也意味着,创作者可以同时使用文字、图片、声音与视频作为输入内容,并直接获得可用的专业影像级输出结果,创作过程不再被拆分为多个工具与步骤。
一直以来,使用AI模型进行视频或图片创作的用户,最关心的就是模型的稳定性与表达力。此次,可灵3.0系列模型的上线增强了视频内容的一致性,通过整合视频主体、音色绑定及“图生视频+主体参考”等一系列技术能力,使得人物形象、动作与声音在复杂镜头切换中保持稳定,文字清晰、品牌标识可识别,即便在多语言场景下,视觉风格与角色特征也能高度统一。
此外,该模型支持最长15秒视频的连续生成,并引入智能分镜与自定义镜头控制,让创作者能够直接组织镜头节奏与叙事结构,不再依赖碎片化拼接,从而让镜头具备情绪递进与画面张力。

















